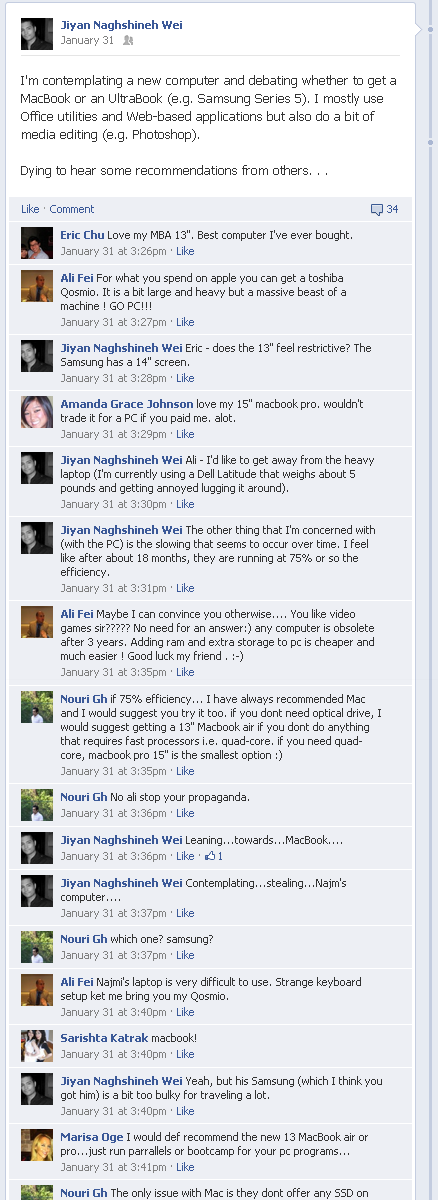
About three months ago I posted a simple question to my Facebook wall, asking whether my next computer should be an Apple or a PC.
Over the next five hours I received over thirty opinions from students, senior executives, computer programmers, analysts and a random assortment of other friends and family. The feedback helped me make an important consumer decision.
From the perspective of your typical Facebook user, I had posted a question and received feedback from my network – a seemingly innocuous act.
Let’s consider what happened from a technological perspective:
My first action (posing the initial question) would have inserted a row in a table (let’s call it StatusUpdate), which would have contained attributes including a post date and post content. This initial action would triggered several subsequent processes (I’ve taken some creative liberties here):
- A task would have run to make certain inferences based on the content. These inferences would update a table where Facebook compiles an index of my interests (ImplicitUserInterests).
- Facebook would use these inferences to determine which contacts (UserContacts) within my network should receive the status update.
- These contacts would have their walls (WallContent) updated with my status update.
- As each contact responded, an additional table indexing their response would be updated (StatusUpdateResponse).
- The content of the response would allow Facebook to make inferences about their interests (ImplicitUserInterests).
- Their response would be shared on their wall (WallContent).
- Facebook would have been able to make an inference about the relationship between the respondent and myself (UserRelationship).
- A bunch of other stuff that I can’t even imagine would have also happened.
We can quickly see how one simple act sets a sequence of events into motion, culminating in the creation of a large set of data.
Now consider the following:
- There are over 500 million users on Facebook.
- Over 700 billion minutes are spent on Facebook each month.
- There are a host of other sites creating an amount of data that is in the same order of magnitude as Facebook.
What does it all add up to?
Here’s a hint: It’s not small data.
“Welcome to the Age of Big Data,” invites Steve Lohr in his recent NY Times piece on Big Data.
While acknowledging that Big Data has the scent of a “meme and a marketing term,” Lohr points out that according to IDC, a technology research firm, data is growing at a rate of 50 percent per year.
Regardless of whether the actual you believe in the veracity of IDC’s estimated rate-of-increase, it’s difficult to dispel the notion that every year, there seems to be significantly more information at your fingertips than the previous year.
It’s this broad acknowledgment that has allowed the concept of “”Big Data” to catch fire.
Like most memes, Big Data comes with a slight feeling of déjà vu – a faint voice in the background tells us that we have seen this before. Those of us who have been working in information technology for the past decade (or longer) recall things like the “Invisible Web” and the “Deep Web.”
Yet there seems to be something categorically different about this latest information “revolution,” that makes us stand up and pay attention.
Over the next several weeks, I’ll be endeavoring to deconstruct what is different about “Big Data” in the hopes that understanding these differences will help us better understand what Big Data actually is and whether we are talking about more hype or perhaps something real.
0 Comments on "Defining Big Data"