
This is a pretty esoteric subject but I’ll try to contextualize to make it a bit more interesting.
In the financial publishing business, it’s a common practice to create profile pages for publicly traded companies so investors can easily get all the information they need at a glance. The profile pages are populated with a bunch of information – SEC filings, key employees, the stock price and news about the company (to name just a few of the content types). Here’s an example of the news showing up on Vocus’ profile page in the business section of SFGate (powered by FinancialContent).
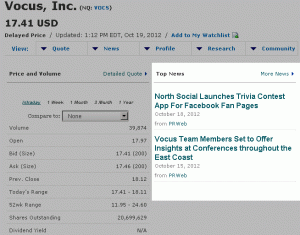
The piece of data that makes all this possible is the company’s ticker symbol – a unique identifier that allows financial publishers to reconcile content about an entity, with that entity. If the article has a ticker symbol, it makes it pretty simple for the publisher to reconcile it with a profile page.
Some publishers have begun looking at ways to reconcile content with a profile page through inference. Google Finance for example, algorithmically determines which stories should be reconciled with a profile page, albeit using the ticker as a major variable. AOL (Daily Finance) is another publisher that algorithmically reconciles content with entities (via Relegence, a 2006 acquisition).
Big Data offers some interesting prospects for financial publishers moving forward. If someone were able to offer a macro-level perspective of conversational trends about a public company on Twitter for example, that would seem to be something that investors would want to see on a profile page. I’d also think that analysis of a company’s shipping records via a trade intelligence solution like ImportGenius, would be a value add to public company pages.
0 Comments on "How financial publishers reconcile news with public company profiles"